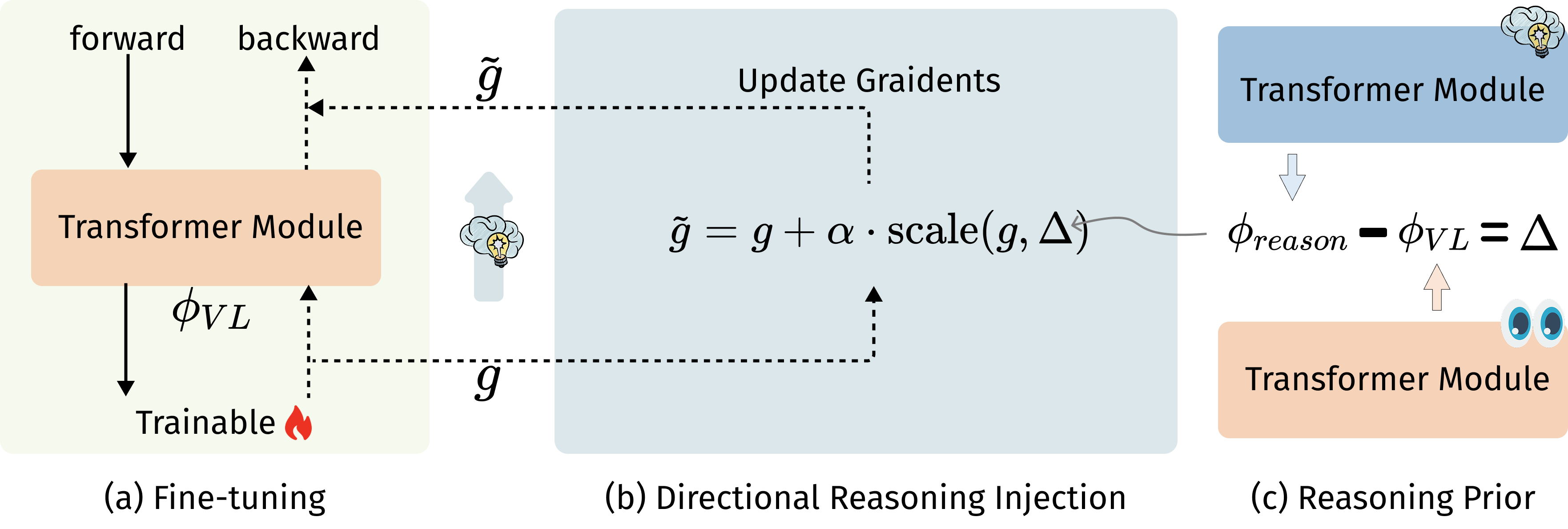
DRIFT
The first method to inject directional reasoning structure into MLLM fine-tuning. Instead of hoping reasoning emerges, we explicitly steer models toward structured, faithful cross-modal inference.
Building AI that can listen, speak, reason, and interact in real time.
Research Scientist, Tencent Hunyuan · Seattle
LLM-based ASR full-duplex models interactive multimodal models
At Tencent Hunyuan, I work on LLM-based speech recognition, full-duplex spoken interaction, and multimodal interaction models. My research focuses on building AI systems that can understand, respond to, and interact with people naturally in real time.
More broadly, my work connects omni-modal LLMs, multimodal reasoning, audio-visual learning, and diffusion-based generation, with an emphasis on learning more from less data and computation.
Ph.D. in Computer Science, University of Rochester · B.Eng., Nanjing University
A few projects that define what I care about.
The first method to inject directional reasoning structure into MLLM fine-tuning. Instead of hoping reasoning emerges, we explicitly steer models toward structured, faithful cross-modal inference.
A zero-shot paradigm shift for audio separation: separate any sound category without ever training on it. Pretrained diffusion priors replace paired training data entirely.
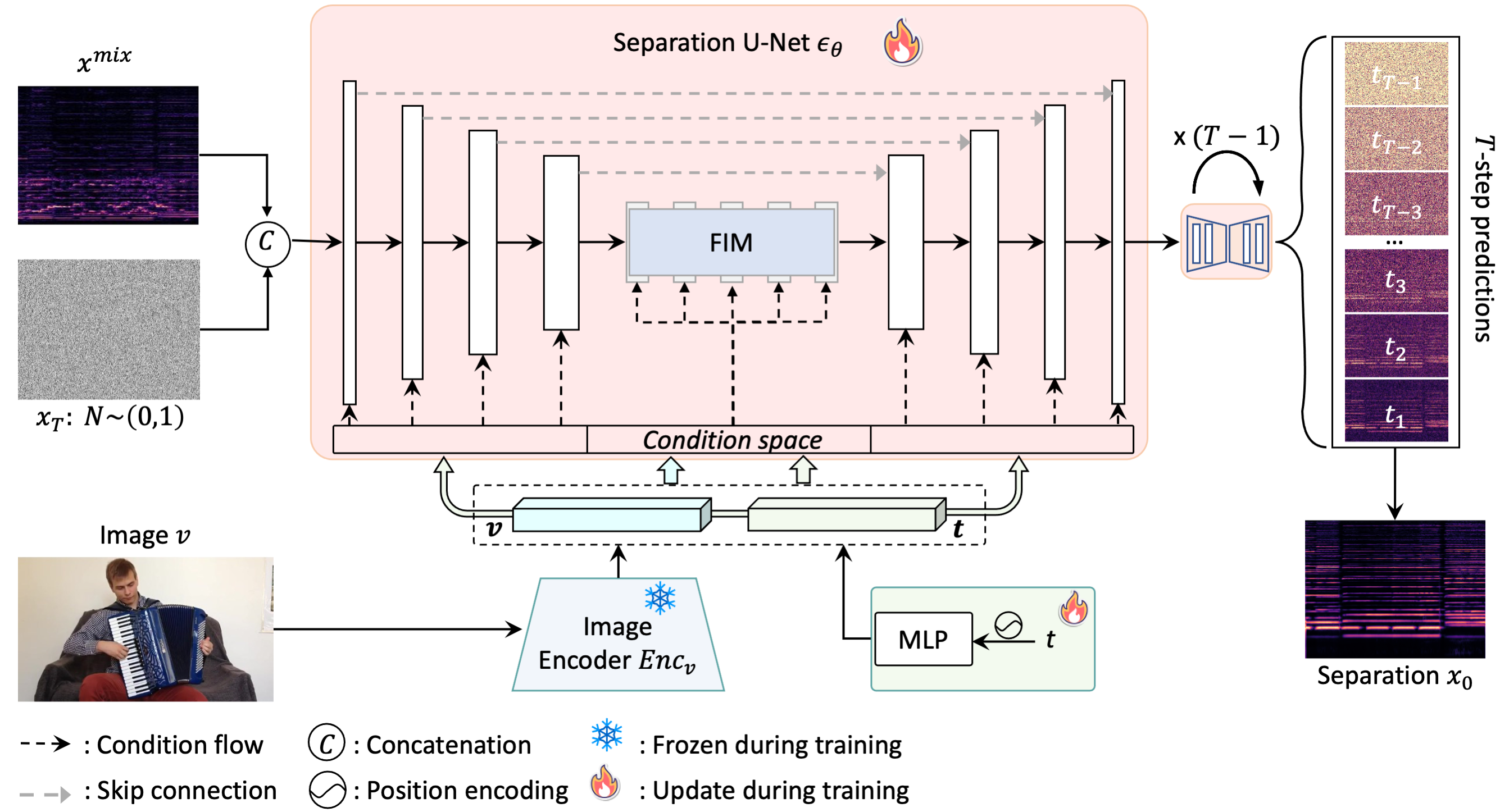
The first generative diffusion approach to visually-guided sound separation, producing high-fidelity audio from diverse real-world mixtures. Best Paper Award at ACCV 2024.
20+ papers at NeurIPS, CVPR, ICCV, ECCV, ICLR, IJCV, and more.
Omni-modal LLM research and deployment at scale.
Multimodal reasoning and efficient adaptation of large language models. Led to DRIFT, accepted at ACL Findings 2026.
Audio-visual learning for cinematic audio highlighting and sound design. Resulted in a CVPR 2025 paper on audio highlighting.
Neural acoustic modeling and spatial audio for human body soundfields. Published at ECCV 2024.
3D point cloud processing and non-local denoising methods.