🌟 Iterative Synthesis
Here, we animate the syntheis process by showing how the separated magnitude spectrogram changes with 100-steps sampling. Specifically, given the visual frames from two videos V(1) and V(2) and the corresponding audio mixture, our model synthsizes the separated spectrograms A(1) and A(2) iteratively and finally outputs clean separated spectrograms. Use the slider here to linearly control the iterative syntheis.

Conditions
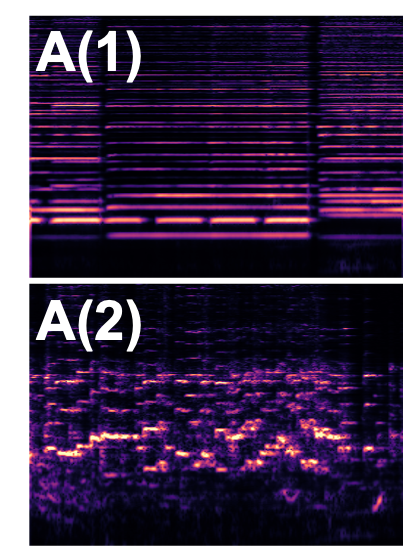
Output
♫ Audio-Visual Separation from Diverse Categories
We show DAVIS's separation results across diverse categories.
Example1: "Baltimore oriole calling" + "gibbon howling"
| Mixture | Frame | Ground Truth | Prediction |
|---|---|---|---|
 |
 |
 |
 |
|
 |
 |
 |
Example2: "cow lowing" + "snake hissing"
| Mixture | Frame | Ground Truth | Prediction |
|---|---|---|---|
 |
 |
 |
 |
|
 |
 |
 |
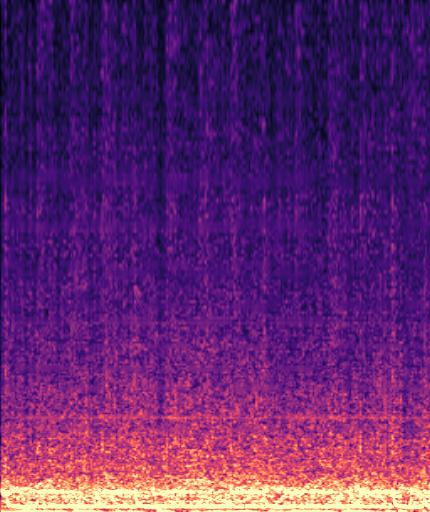
Example3: "fire truck siren" + "helicopter"
| Mixture | Frame | Ground Truth | Prediction |
|---|---|---|---|
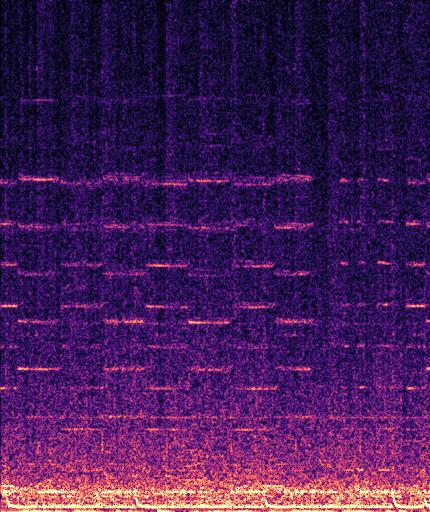 |
 |
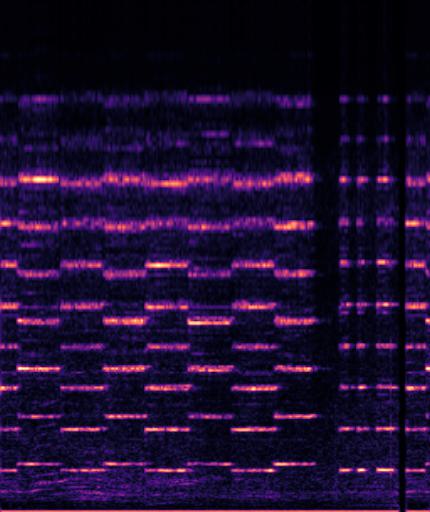 |
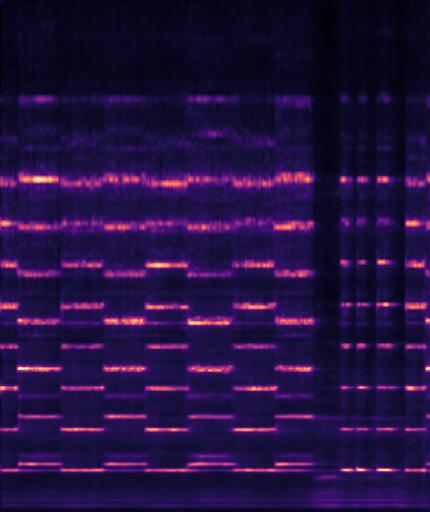 |
|
 |
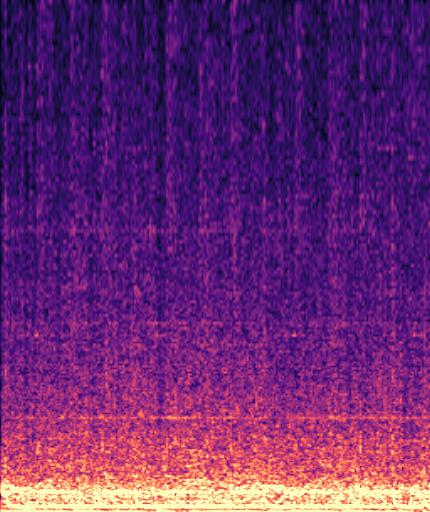 |
 |
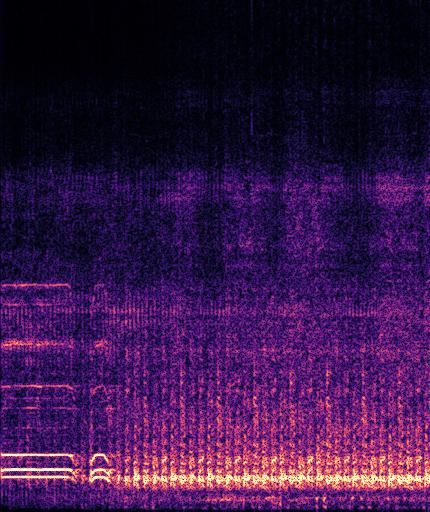
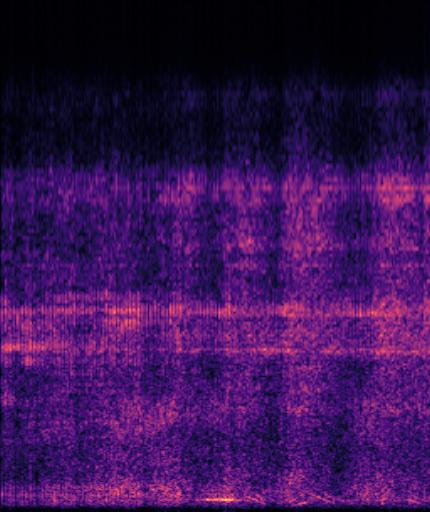
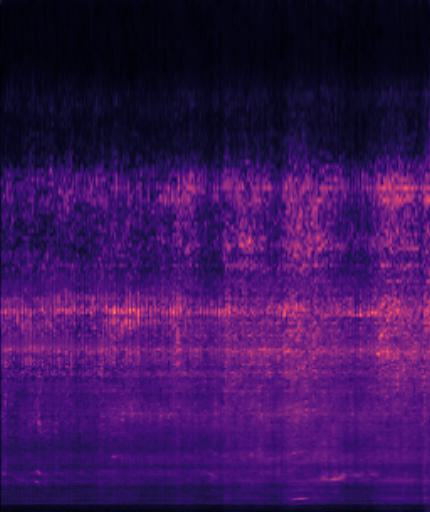
Example4: "driving motorcycle" + "train whistling"
| Mixture | Frame | Ground Truth | Prediction |
|---|---|---|---|
 |
 |
 |
 |
|
 |
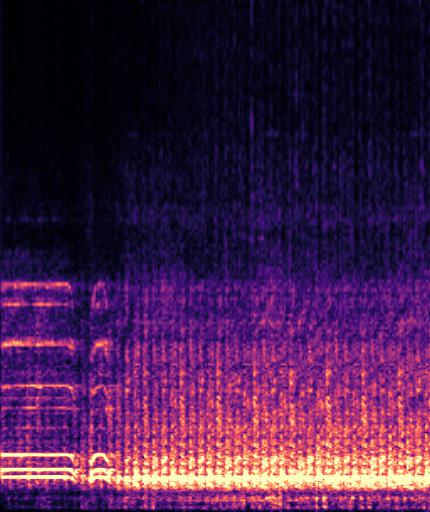 |
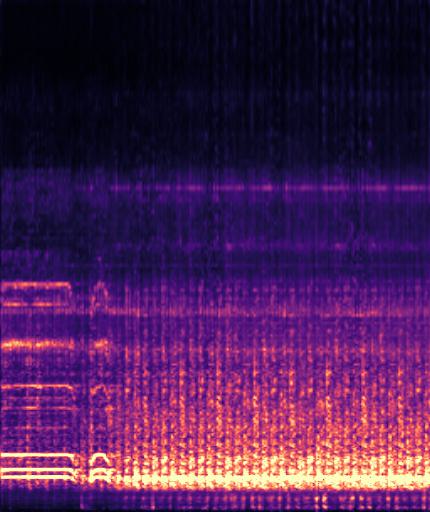 |
♫ Example results on MUISC dataset
Settings: We take audio samples of different categories in the MUSIC dataset and mix the two sources. Then we use their corresponding frames to separate the sources respectively. Comparisons between Ground Truth, DAVIS, and iQuery are provided. DAVIS clearly achieves better separation quality. Note that for each example, the two mixtures are the same.
Example1: "Accordion" + "Violin"
| Mixture | Frame | Ground Truth | Prediction (DAVIS) | Prediction (iQuery) |
|---|---|---|---|---|
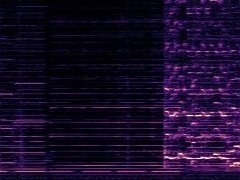 |
 |
 |
 |
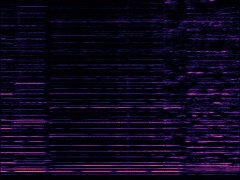 |
|
 |
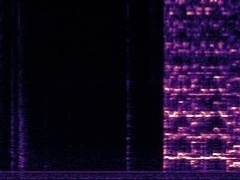 |
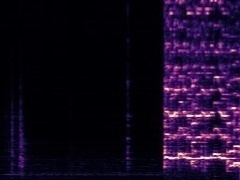 |
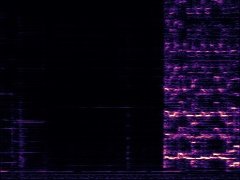 |
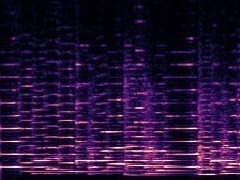
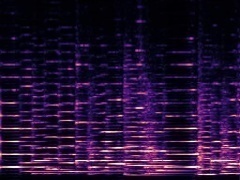
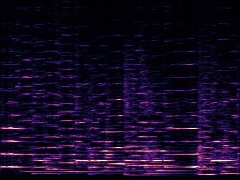
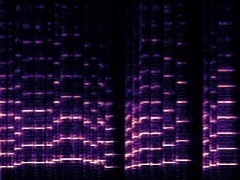
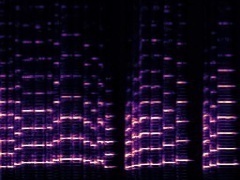
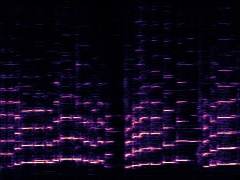
Example2: "Cello" + "Trumpet"
| Mixture | Frame | Ground Truth | Prediction (DAVIS) | Prediction (iQuery) |
|---|---|---|---|---|
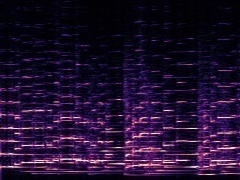 |
 |
 |
 |
 |
|
 |
 |
 |
 |
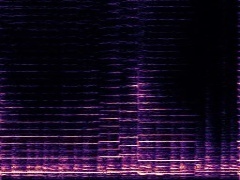
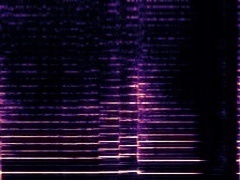
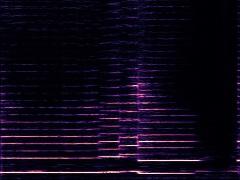
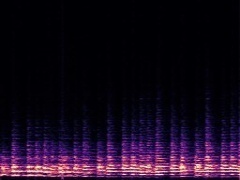
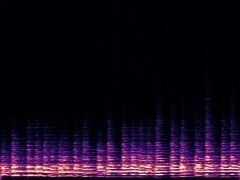
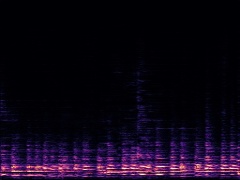
Example3: "Clarinet" + "Tuba"
| Mixture | Frame | Ground Truth | Prediction (DAVIS) | Prediction (iQuery) |
|---|---|---|---|---|
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
Example4: "erhu" + "Saxophone"
| Mixture | Frame | Ground Truth | Prediction (DAVIS) | Prediction (iQuery) |
|---|---|---|---|---|
 |
 |
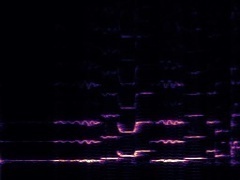 |
 |
 |
|
 |
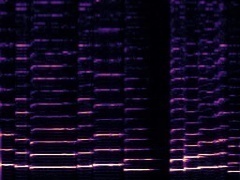 |
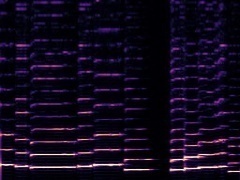 |
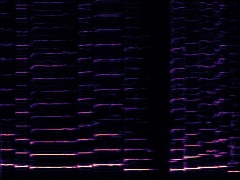 |
♬ Example results on AVE dataset
Settings: We take audio samples of different categories in the AVE dataset and mix the two sources. DAVIS clearly achieves better separation quality across diverse categories. Note that for each example, the two mixtures are the same.
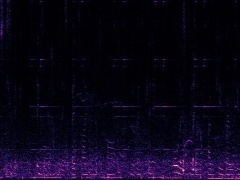
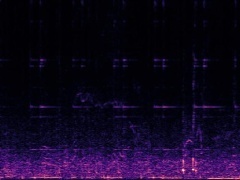
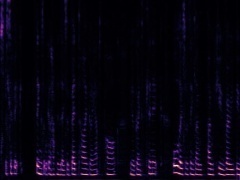
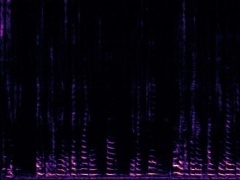
Example1: "Clock" + "Woman speaking"
The background noise in the "Clock" video is also dropped by the model as no related visual information presents in the frame.
| Mixture | Frame | Ground Truth | Prediction (DAVIS) | Prediction (iQuery) |
|---|---|---|---|---|
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
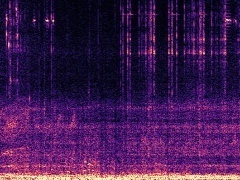
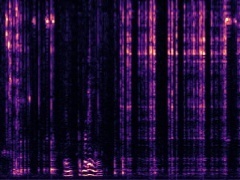
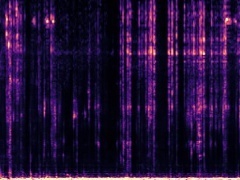
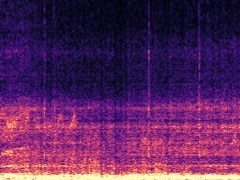
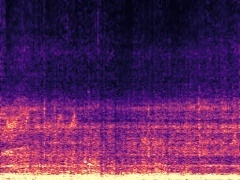
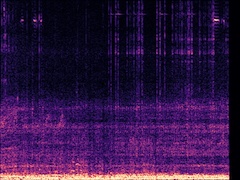
Example2: "Rats" + "Motorcycle"
The background speech in the "Rats" video is also dropped by the model as no "human" presents in the frame.
| Mixture | Frame | Ground Truth | Prediction (DAVIS) | Prediction (iQuery) |
|---|---|---|---|---|
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
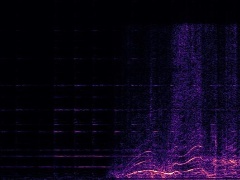
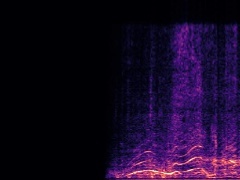
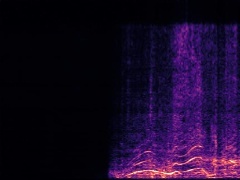
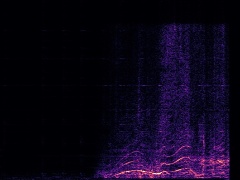
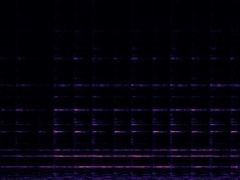
Example3: "Race car" + "Church bell"
| Mixture | Frame | Ground Truth | Prediction (DAVIS) | Prediction (iQuery) |
|---|---|---|---|---|
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
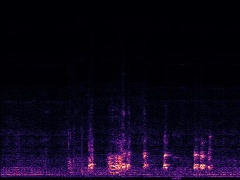
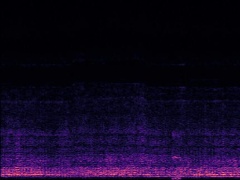
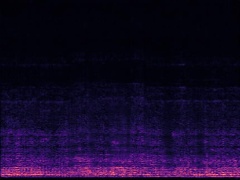
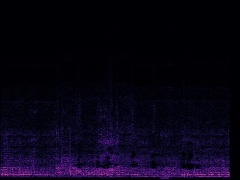
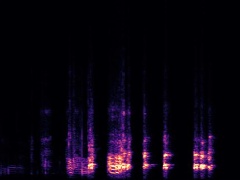
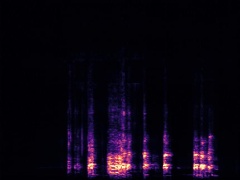
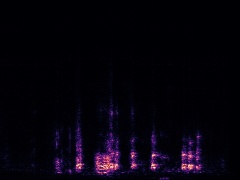
Example4: "Helicopter" + "Bark"
| Mixture | Frame | Ground Truth | Prediction (DAVIS) | Prediction (iQuery) |
|---|---|---|---|---|
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
☞ Application: Zero-Shot Text-Guided Separation
We show an application: Zero-Shot Text-Guided Source Separation, which utilizes our trained audio-visual separation model to enable text query at inference. During training, we use CLIP-image encoder to extract the visual embeddings as conditions. Thanks to the strong capabilities of the CLIP model, which aligns corresponding image and text features into closely matched embeddings, we can use the text features generated by the CLIP-text encoder from a text query in a zero-shot setting. Combining the parsing capability from Large Language Models, our model can further allow for user-instructed sound separation, i.e., user can use our audio-visual model to separate sounds by providing their insturctions in the form of text.
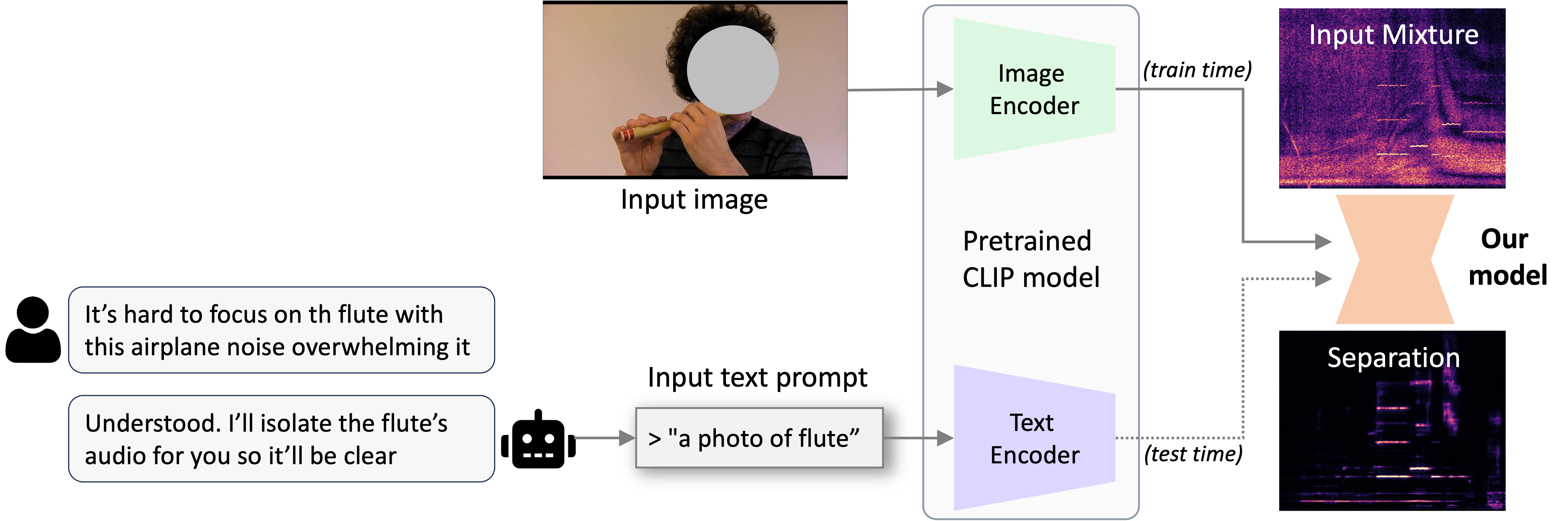
During testing, text prompts are used as conditions to the DAVIS model, which is trained with images as conditions.
| Mixture: Helicopter + Train Horn | Prompt: "A photo of Helicopter." | Prompt: "A photo of Train Horn." |
| Mixture: Shofar + Motorcycle | Prompt: "A photo of Shofar." | Prompt: "A photo of Motorcycle." |
| Mixture: Church bell + Female speech | Prompt: "A photo of Church bell." | Prompt: "A photo of Female speech." |