Chao Huang
|
I am a researcher at Tencent HunYuan, Seattle. I am completing my PhD at University of Rochester, advised by Chenliang Xu. I study multimodal learning and generation. Email / CV / Google Scholar |
|
|
|
| [01/2026] | XModBench is accepted to ICLR 2026 and CAT-V won the AAAI 2026 Best Demo Award, Runner-up! |
| [01/2026] | Joined Tencent HunYuan as a full-time researcher! |
| [10/2025] | Received the NeurIPS 2025 Scholar Award! |
| [09/2025] | Three papers accepted to NeurIPS 2025 and one paper accepted to IJCV! |
| [08/2025] | Selected for ICCV 2025 Doctoral Consortium! |
| [06/2025] | One paper accepted to ICCV 2025! See you in Hawaii. |
| [04/2025] | I am co-organizing the 🔒 TrustFM: Workshop on Trustworthy Foundation Models @ ICCV 2025! |
| [04/2025] | |
| [02/2025] | Two papers accepted to CVPR 2025! See you in Nashville 🎸. |
| [12/2024] | 🏆 DAVIS won the ACCV 2024 Best Paper Award, Honorable Mention! |
| [09/2024] | Two papers accepted to ACCV 2024 with DAVIS as Oral presentation. See you in Hanoi, Vietnam 🍜. |
| [07/2024] | Acoustic Primitives is accepted to ECCV 2024! See you in Milan ⛪. |
| [05/2024] | I have rejoined Meta Reality Labs as a summer research intern, this time based in the UK. |
| [09/2023] | One paper accepted to NeurIPS 2023! |
| [06/2023] | Invited paper talk at Joint International 3rd Ego4D and 11th EPIC Workshop @ CVPR 2023. |
| [03/2023] | I will be joining Meta Reality Labs Pittsburgh for summer internship! |
| [02/2023] | One paper accepted to CVPR 2023! |
|
|
|
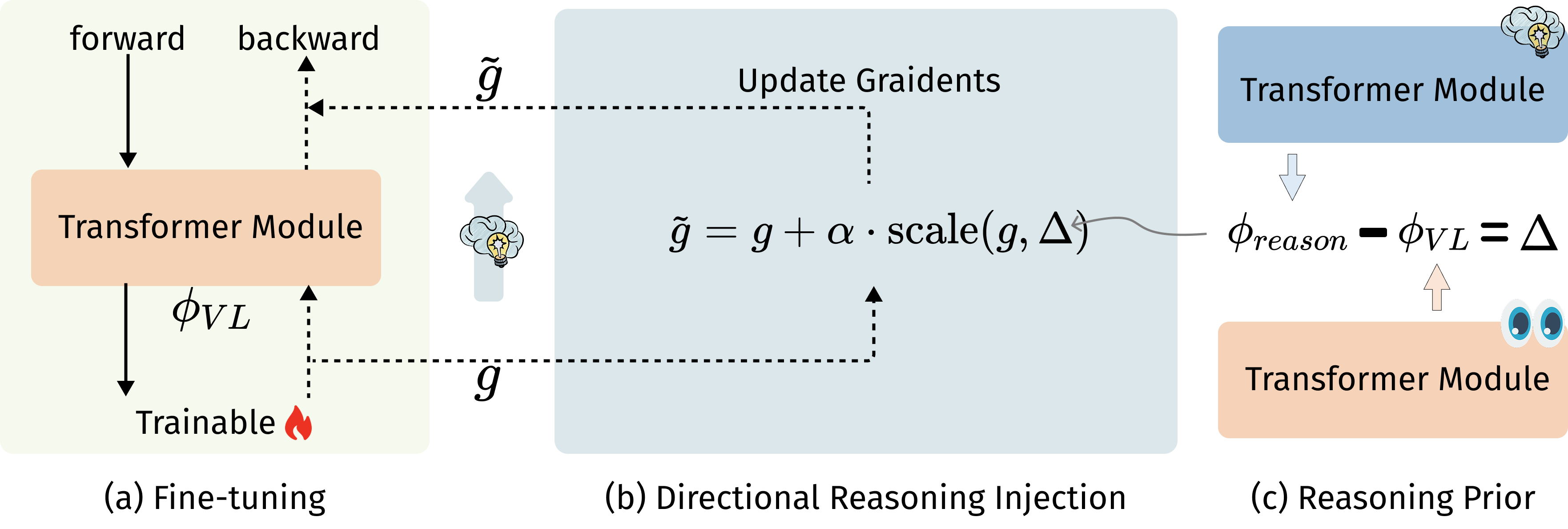
Chao Huang, Zeliang Zhang, Jiang Liu, Ximeng Sun, Jialian Wu, Xiaodong Yu, Ze Wang, Chenliang Xu, Emad Barsoum, Zicheng Liu arXiv preprint, 2025 Paper / Project Page / Code DRIFT transfers reasoning from DeepSeek-R1 into QwenVL via gradient-space guidance, improving multimodal reasoning without destabilizing alignment or expensive RL. |
|
Yunlong Tang, Jing Bi, Chao Huang, Susan Liang, Daiki Shimada, Hang Hua, Yunzhong Xiao, Yizhi Song, Pinxin Liu, Mingqian Feng, Junjia Guo, Zhuo Liu, Luchuan Song, Ali Vosoughi, Jinxi He, Liu He, Zeliang Zhang, Jiebo Luo, Chenliang Xu AAAI Demonstration Program, 2026 🏆 Best Demo Award, Runner-up Paper / Video / Code Fine-grained object-centric video captioning using spatiotemporal multimodal prompting. |

|
Xingrui Wang, Jiang Liu, Chao Huang, Xiaodong Yu, Ze Wang, Ximeng Sun, Jialian Wu, Alan Yuille, Emad Barsoum, Zicheng Liu ICLR, 2026 Paper / Project Page / Code / Data A benchmark for evaluating cross-modal capabilities and consistency in omni-language models. |
|
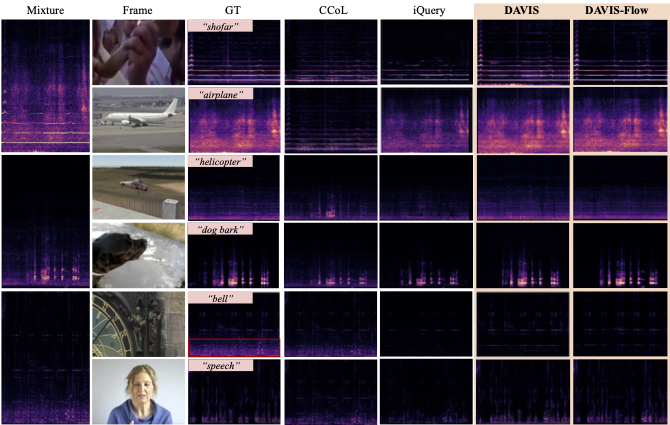
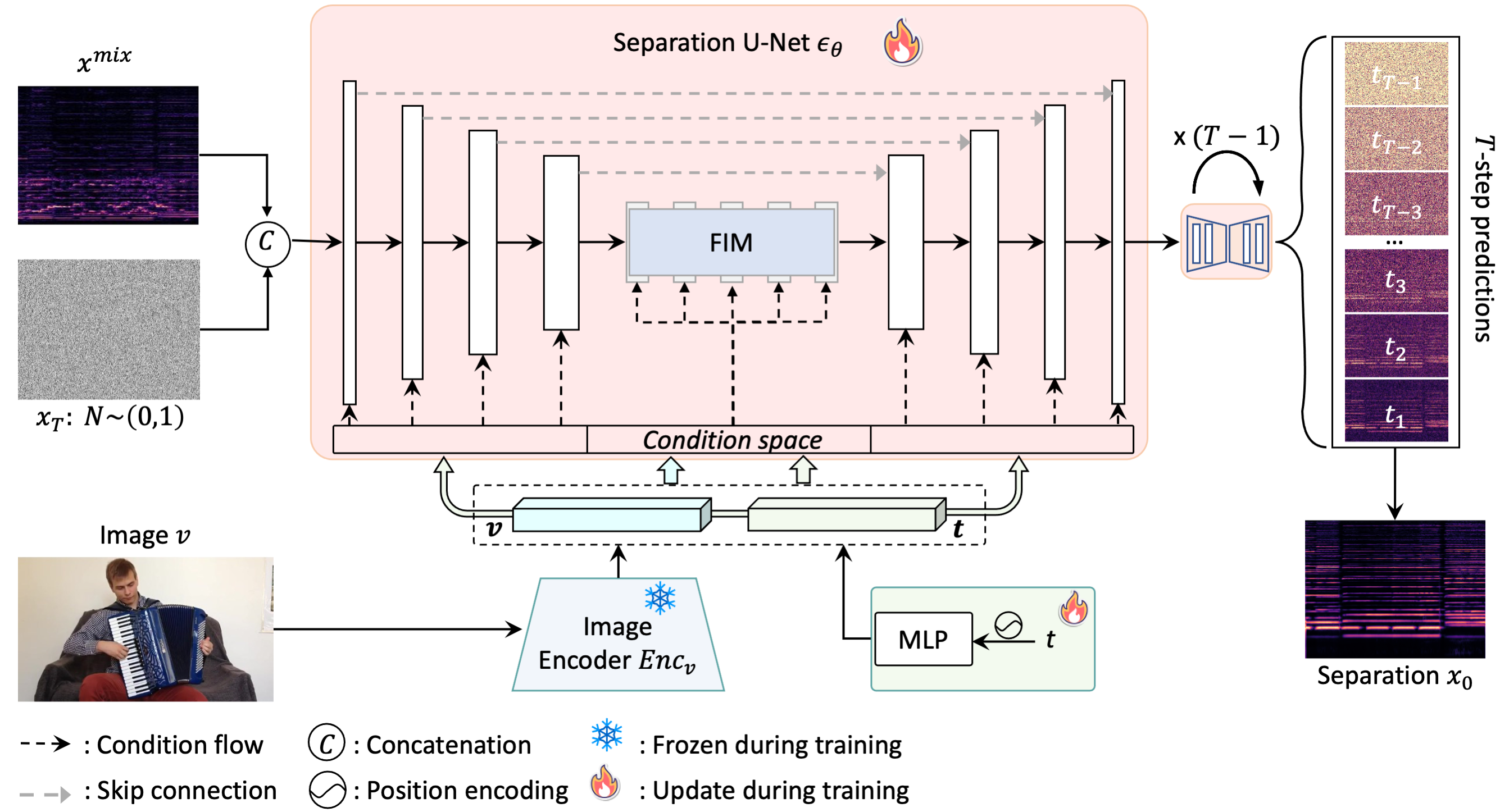
Chao Huang, Susan Liang, Yapeng Tian, Anurag Kumar, Chenliang Xu IJCV, 2025 Paper / Project Page / Code How generative models can improve sound separation across diverse categories with visually-guided training. |
|
|
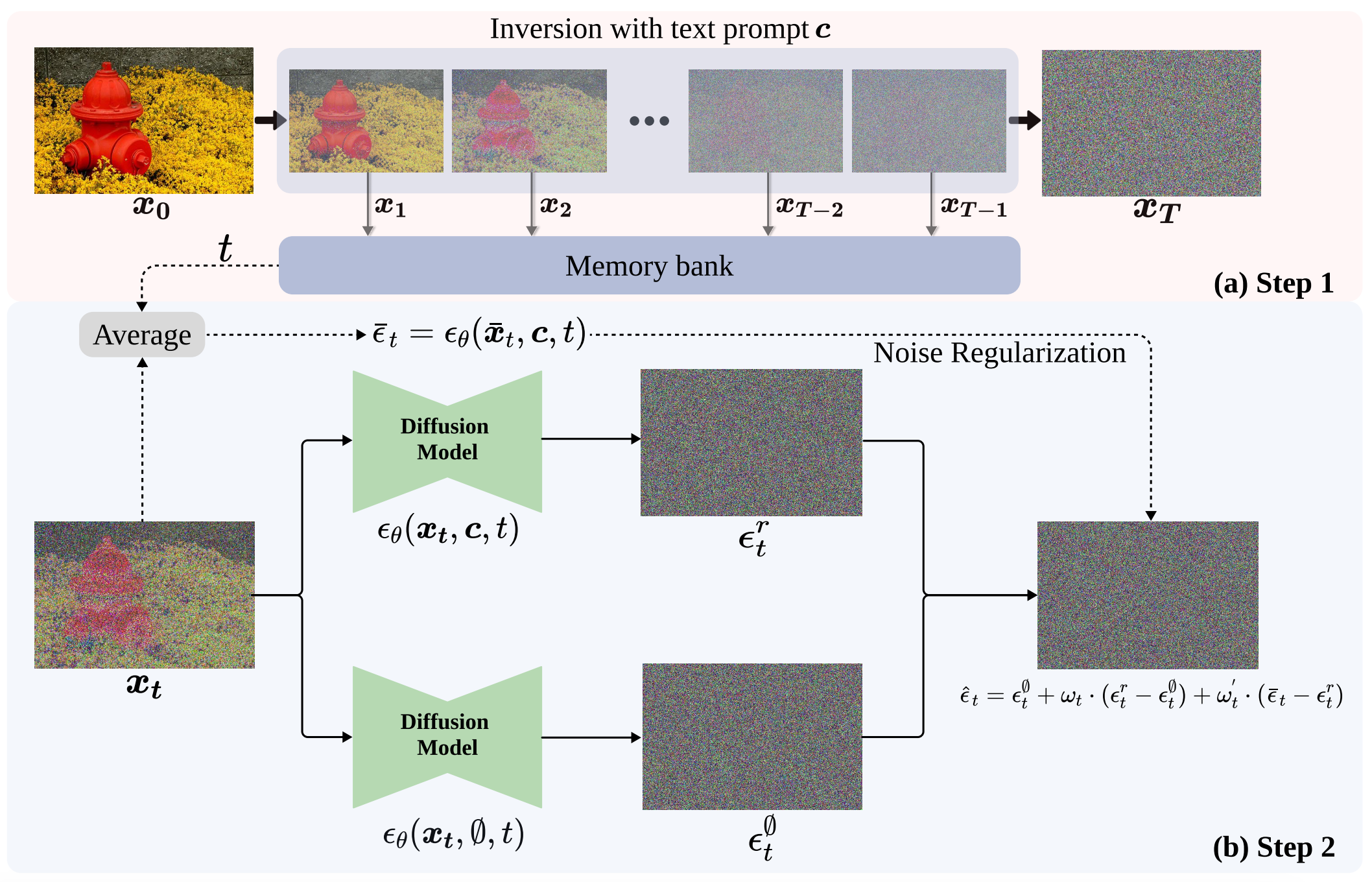
Chao Huang, Yuesheng Ma, Junxuan Huang, Susan Liang, Yunlong Tang, Jing Bi, Wenqiang Liu, Nima Mesgarani, Chenliang Xu NeurIPS, 2025 Paper / Project Page / Code No fine-tuning, no task-specific data, just latent inversion + text-conditioned denoising to isolate any sound you describe. |
|
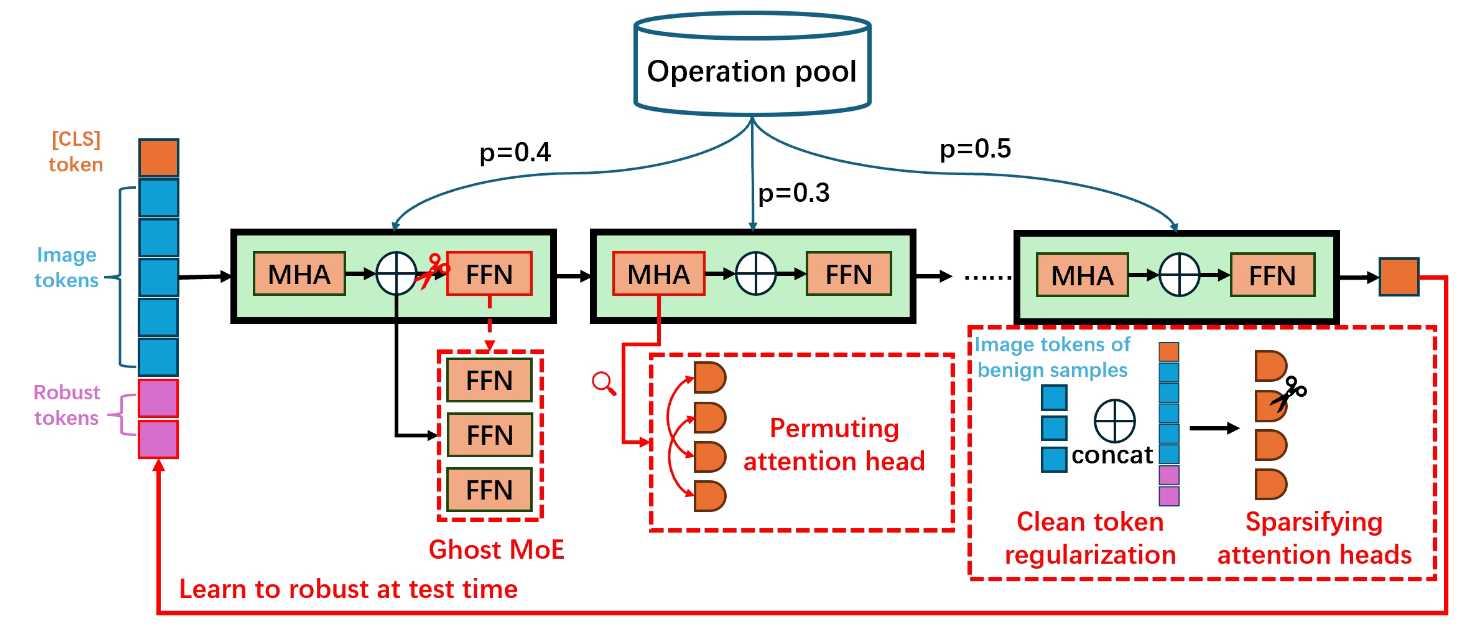
Jiani Liu*, Zhiyuan Wang*, Zeliang Zhang*, Chao Huang, Susan Liang, Yunlong Tang, Chenliang Xu. NeurIPS, 2025 Paper We propose a bag of tricks to boost the adversarial transferability of ViT-based attacks. |
|
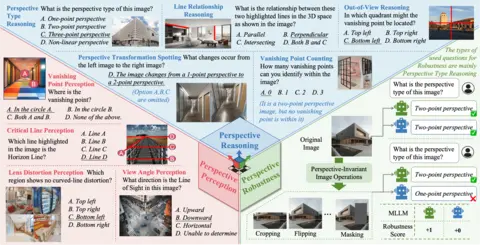
Yunlong Tang, Pinxin Liu, Mingqian Feng, Zhangyun Tan, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, and Ali Vosoughi, Luchuan Song, Zeliang Zhang, Chenliang Xu NeurIPS, 2025, Datasets and Benchmarks Paper / Project Page / Code Introducing MMPerspective, a comprehensive benchmark for MLLMs on perspective understanding. |
|
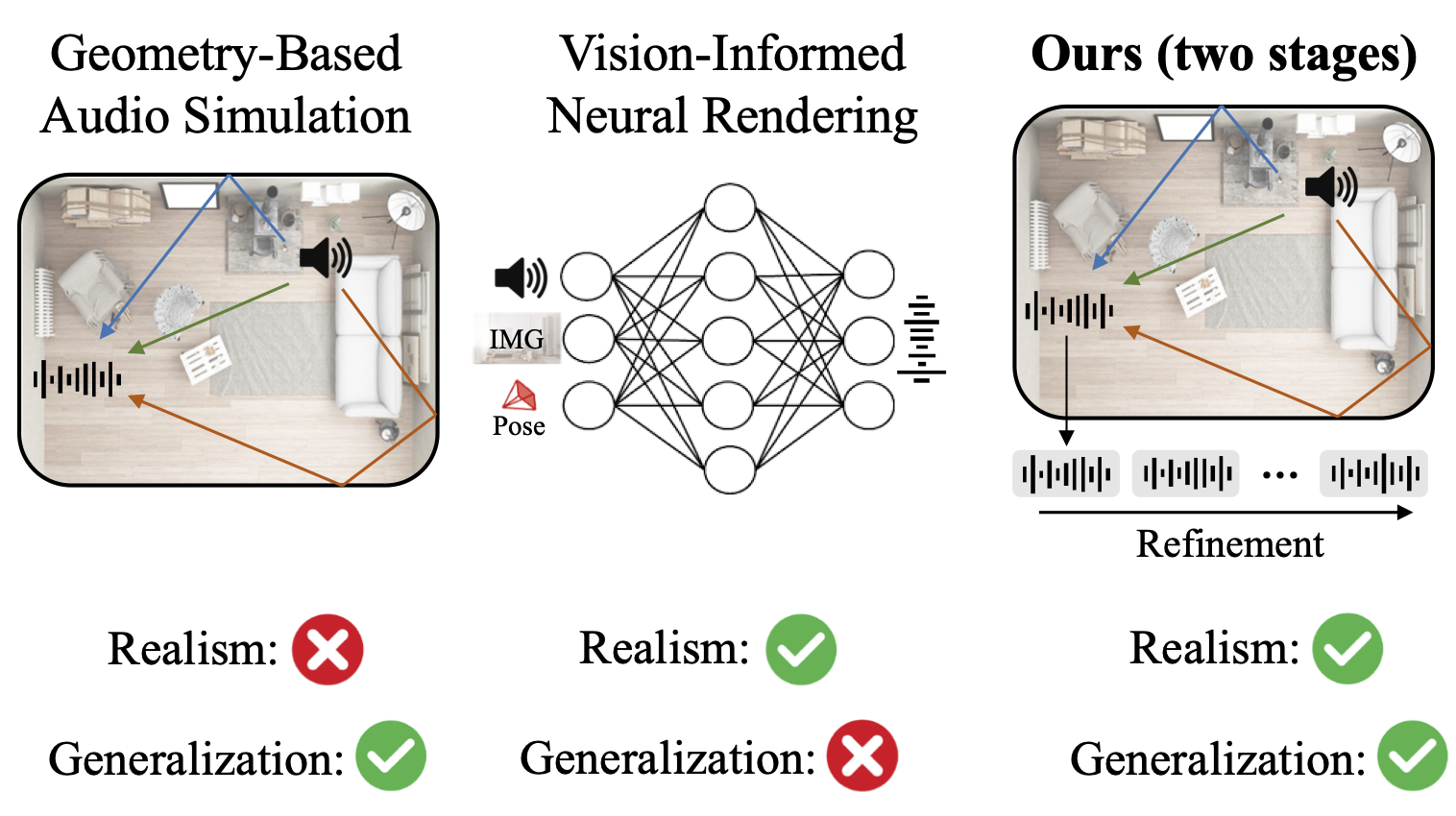
Susan Liang, Chao Huang, Yunlong Tang, Zeliang Zhang, Chenliang Xu ICCV, 2025 π-AVAS is a two-stage framework that combines physics-based vision-guided audio simulation for generalization with flow-matching audio refinement for realism. |

|
Chao Huang, Susan Liang, Yunlong Tang, Li Ma, Yapeng Tian, Chenliang Xu CVPR GMCV, 2025 Paper / Project Page / Code Where and why you should care about frequency space in diffusion models. |

|
Chao Huang, Ruohan Gao, J. M. F. Tsang, Jan Kurcius, Cagdas Bilen, Chenliang Xu, Anurag Kumar, Sanjeel Parekh CVPR, 2025 Paper / Project Page / Code / Dataset We learn from movies to transform audio to deliver appropriate highlighting effects guided by the accompanying video. |
|
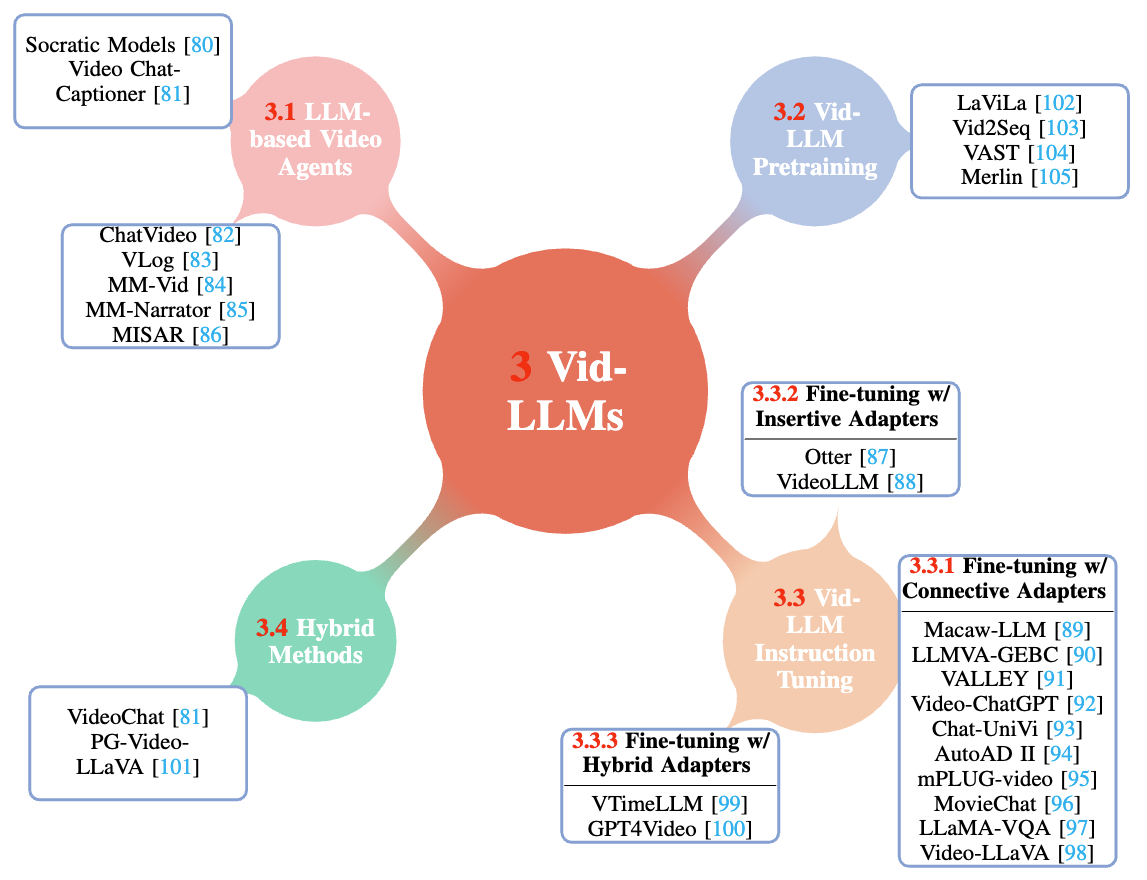
Yunlong Tang*, ... , Chao Huang, ... , Ping Luo, Jiebo Luo, Chenliang Xu IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025 Paper / Project Page A survey on the recent Large Language Models for video understanding. |
|
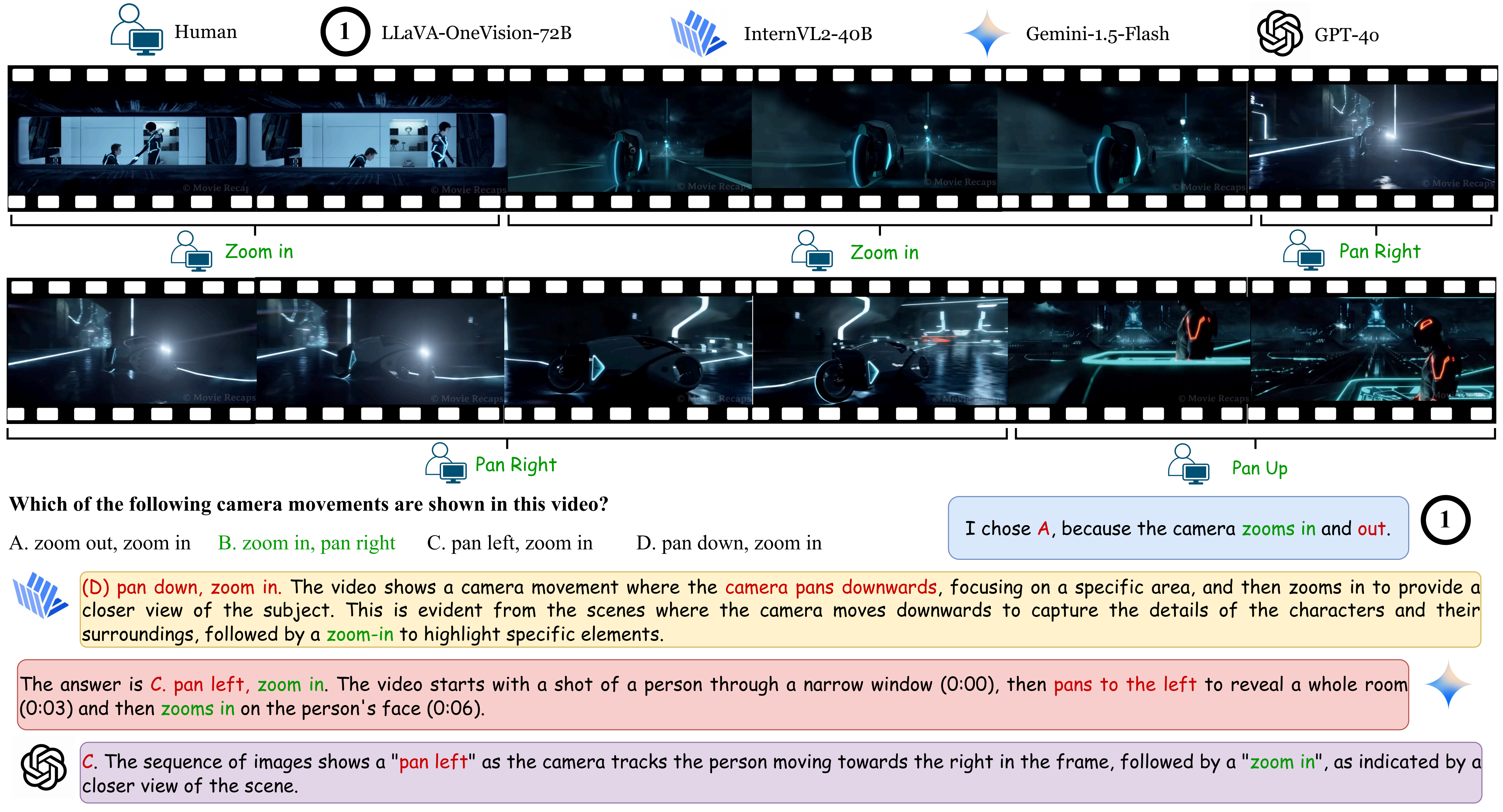
Yunlong Tang*, Junjia Guo*, Hang Hua, Susan Liang, Mingqian Feng, Xinyang Li, Rui Mao, Chao Huang, Jing Bi, Zeliang Zhang, and Pooyan Fazli, Chenliang Xu CVPR, 2025 Paper / Project Page / Code We introduce VidComposition, a benchmark designed to assess MLLMs' understanding of video compositions |
|
Chao Huang, Susan Liang, Yunlong Tang, Yapeng Tian, Anurag Kumar, Chenliang Xu arXiv preprint, 2024 Paper / Project Page / Code We use pretrained text-guided diffusion models to scale up/down concepts in image/audio. |
|
Chao Huang, Susan Liang, Yapeng Tian, Anurag Kumar, Chenliang Xu ACCV, 2024 🏆 Best Paper Award, Honorable Mention Paper / Project Page / Code A new take on the audio-visual separation problem with the recent generative diffusion models. |

|
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu ACCV, 2024 Paper / Project Page / Dataset We achieve joint audio-visual editing under language guidance. |
|
Chao Huang, Dejan Markovic, Chenliang Xu, Alexander Richard ECCV, 2024 Paper / Project Page Thinking of the equivalent of 3D Gaussian Splatting and volumetric primitives for the human body soundfield? Here, we introduce Acoustic Primitives. |
|
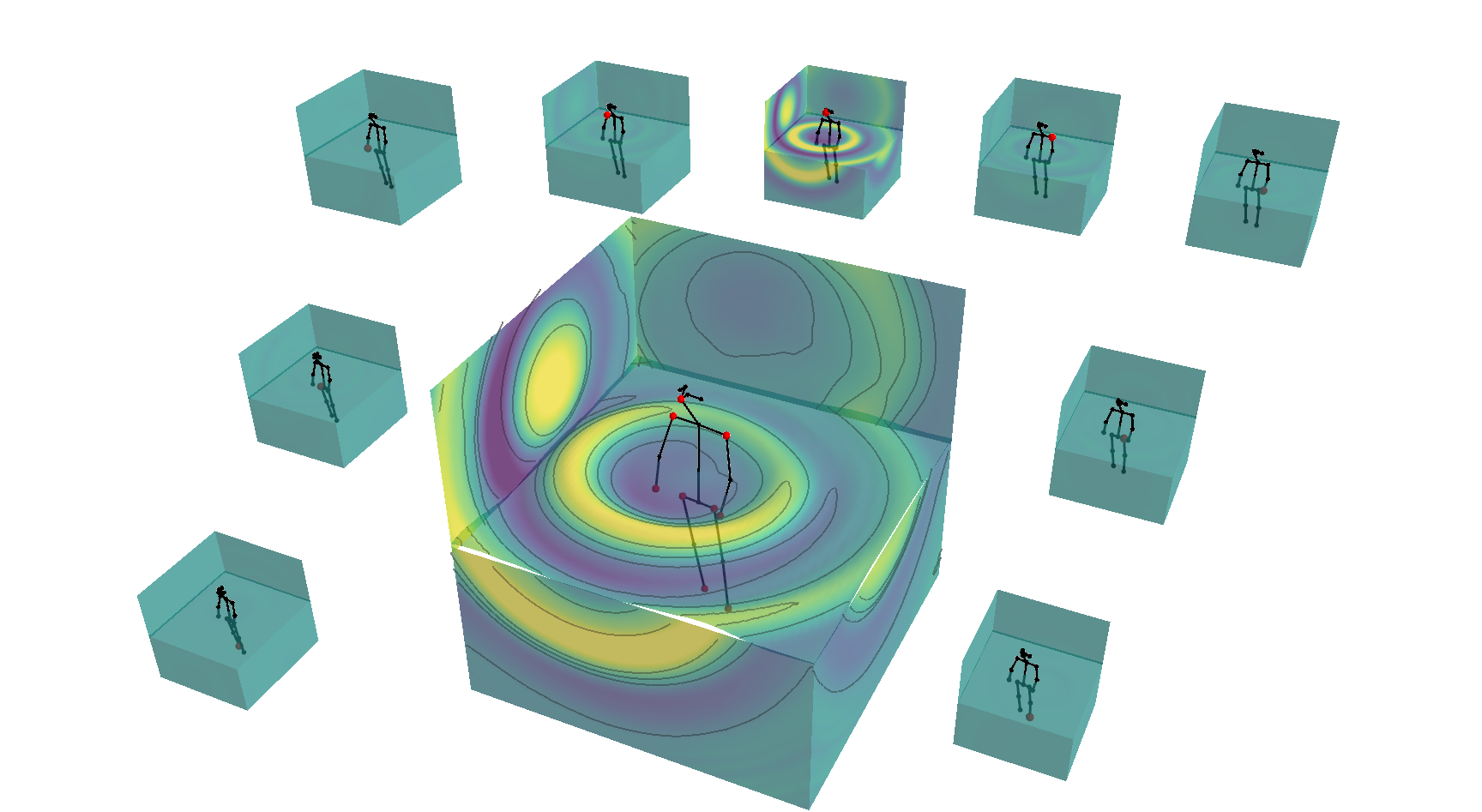
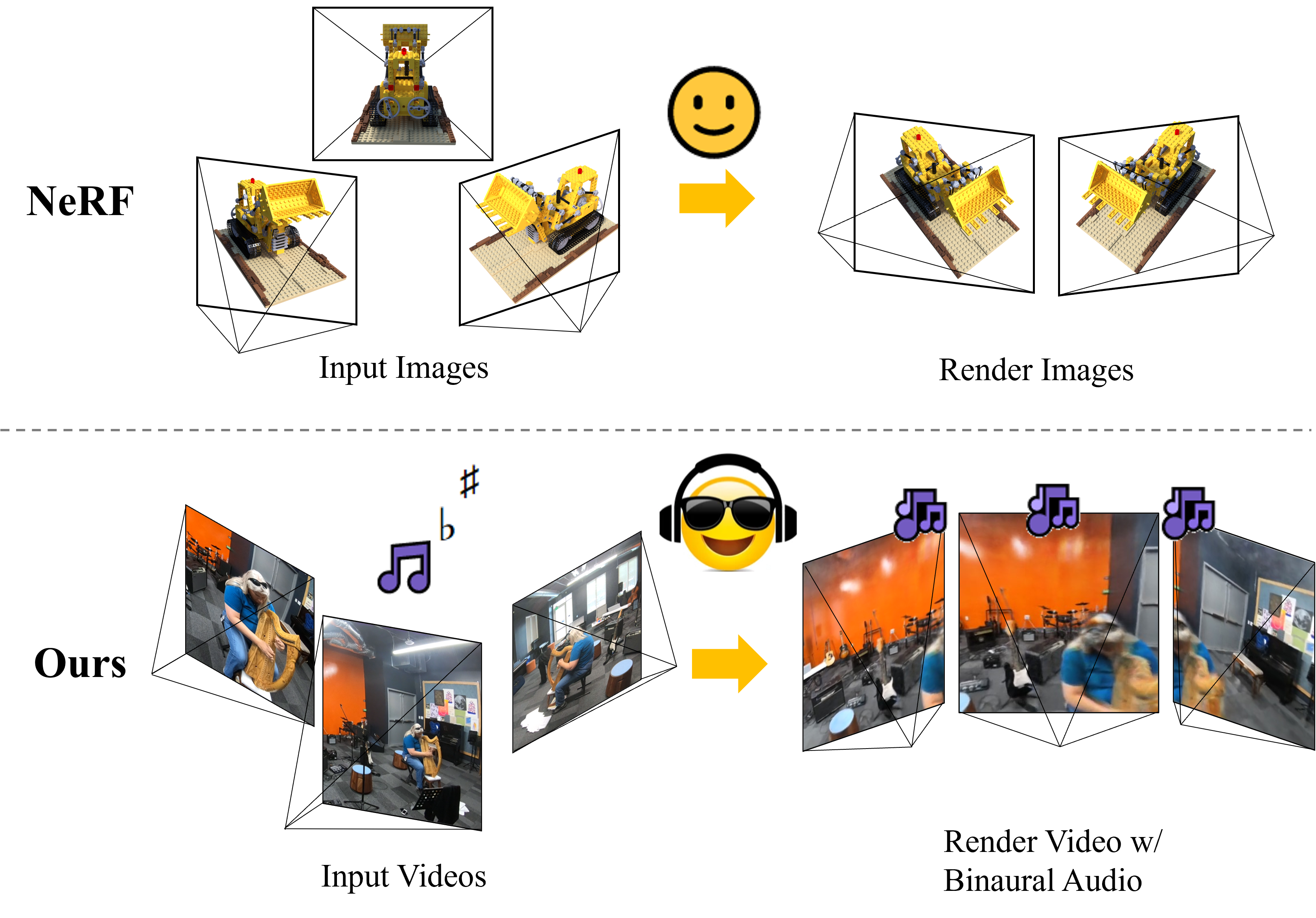
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu NeurIPS, 2023 Paper / Project Page / Code We propose a novel method of synthesizing real-world audio-visual scenes at novel positions and directions. |
|
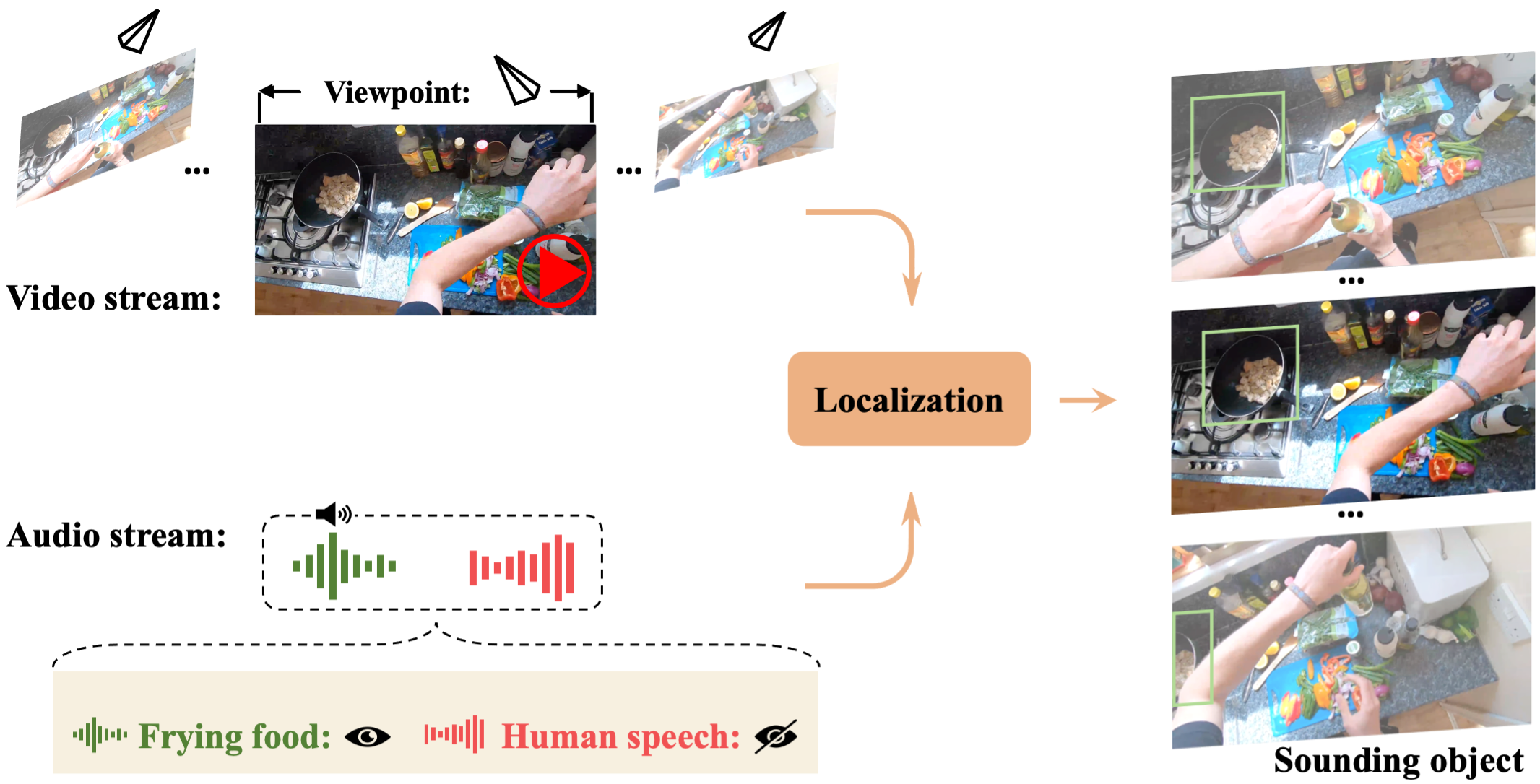
Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu CVPR, 2023 Paper / Code We explore the problem of sound source visual localization in egocentric videos, propose a new localization method and establish a benchmark for evaluation. |
|
Chao Huang*, Ruihui Li*, Xianzhi Li, Chi-Wing Fu arXiv preprint, 2020 A non-local attention based method for point cloud denoising in both synthetic and real scenes. |

|
Chao Huang, Haojie Liu, Tong Chen, Qiu Shen, Zhan Ma IEEE Visual Communications and Image Processing (VCIP), 2019 (Oral Presentation) An image compression system under extreme condition, e.g., < 0.05 bits per pixel (bpp). |
|
|
|
University of Rochester, NY, USA
Ph.D. in Computer Science Jan. 2021 - Present Advisor: Chenliang Xu |
|
|
Nanjing University, Nanjing, China
B.Eng in Electronic Science and Engineering Sept. 2015 - Jun. 2019 |
|
|
|
AMD Research, Remote
Research Scientist Intern May. 2025 - Aug. 2025 Mentor: Jiang Liu, Zicheng Liu |
|
|
Meta Reality Labs Research, Meta, Cambridge, UK
Research Scientist Intern May. 2024 - Aug. 2024 Mentor: Sanjeel Parekh , Ruohan Gao, Anurag Kumar |
|
|
Codec Avatars Lab, Meta, Pittsburgh
Research Scientist Intern May. 2023 - Nov. 2023 Mentor: Dejan Markovic , Alexander Richard |
|
|
The Chinese University of Hong Kong, Shatin, Hong Kong
Research Assistant Jul. 2019 - Dec. 2020 Advisor: Chi-Wing Fu |
|
|
| 2026 | AAAI 2026 — Best Demo Award, Runner-up! |
| 2025 |
NeurIPS 2025 — Scholar Award
ICCV 2025 Doctoral Consortium — Selected Participant |
| 2024 | ACCV 2024 — Best Paper Award, Honorable Mention for “DAVIS: High-Quality Audio-Visual Separation with Generative Diffusion Models” |
|
|
| Workshop Organization |
|
| Conference Reviewing |
|
| Journal Reviewing |
|
|
The template is based on Jon Barron's website. 
|